 This blog was written by Summer 2023 DDL Student RA Nageen Rameez.
This blog was written by Summer 2023 DDL Student RA Nageen Rameez.
Effective climate action requires reliable data to track progress and hold governments and companies accountable to their established climate commitments. As a summer research assistant at the Data-Driven EnviroLab (DDL) and newcomer to the complex world of data-driven climate action research, it was crucial for me to understand the role of data interoperability as the backbone to data-driven analyses conducted for faciliating policy interventions. Through my time working with DDL, I was able to gain deeper insights into why organized, interoperable data is necessary to track global climate progress, particularly through my work on this year’s Global Climate Action (GCA) report. Not only did working on the GCA project teach me why data interoperability is important, but also how we can go about enhancing this interoperability in the first place.
The Global Need for Better Data
The Climate Action Data 2.0 (CAD2.0) community, of which the DDL is a convening member, is working to bridge data gaps that hinder tracking progress towards meeting commitments made in the Paris Agreement. Although the United Nations Framework Convention on Climate Change (UNFCCC) has primarily focused on tracking and facilitating climate action by nation-states, or parties to the UNFCCC, the 2015 Paris Agreement emphasized the importance of Non-State Actors (NSAs), in contributing actions to support driving down global emissions and limiting warming to 1.5 degrees Celsius higher than pre-industrial temperatures (UNFCCC, 2015). To showcase and demonstrate which NSAs are delivering on their climate pledges, the UNFCCC’s Global Climate Action Portal (GCAP) provides an overview, obtaining data from a range of reporting platforms (like CDP) and the Climate Initiatives Platform.
Unfortunately, much of NSA data is collected and stored using heterogeneous methods and taxonomies, making comparison of progress across time and across actors difficult. Existing data collection and storage systems were not built with the goal of aggregating progress and holding NSAs accountable. As a result, NSAs’ contribution to global climate efforts has been historically overlooked. In June of 2023, as the UN Secretary General has made calls to combat “greenwashing,” the UNFCCC announced a landmark Recognition and Accountability framework for Non-State Actors to draw attention to the need for more transparency and accountability of NSA efforts.
Ensuring the interoperability of data shared and used across different collaborators is crucial to CAD2.0’s mission. Data interoperability refers to standardized data formatting to enable coordinated exchange of information, facilitating seamless data exchange. This interoperability allows for easier exchange, aggregation, and comparison of climate data, since it relies on common definitions and metadata (i.e., data about the data that explains the meanings of variables and critical information like units, sources, etc.) Currently, most data scientists, researchers, and students working in the climate data space spend an enormous amount of time compiling datasets and “cleaning” them so that further analysis or modeling can be done. For example, if you’re trying to get a more complete picture of how U.S. cities are contributing to climate change, you might collect datasets on their population, area, GDP, energy sources, and carbon dioxide emissions. Each one of these variables might come from different data sources, and you might find multiple data sources that have the same variables. So how do we make sense of all these disparate datasets? By making them interoperable – ensuring that each dataset consistently refers to the city names in the correct way and that variables claiming to measure the same thing actually are.
DDL’s Contributions to Data Interoperability
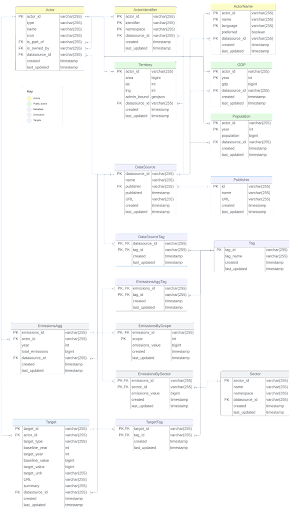 Thankfully, DDL has been working on the issue of climate data interoperability for several years as part of its “Global Climate Action of Cities, Regions and Companies” (GCA) reports, which began in 2018 with the goal of aggregating NSA climate mitigation contributions. To accomplish this task, DDL developed custom machine learning-aided algorithms and data dictionaries to harmonize these reports, which include data from more than a dozen disparate sources. These functions and data dictionaries form the ClimActor R package, an open-source software that allows for anyone to use our cleaning algorithms to harmonize climate actors’ data.
Thankfully, DDL has been working on the issue of climate data interoperability for several years as part of its “Global Climate Action of Cities, Regions and Companies” (GCA) reports, which began in 2018 with the goal of aggregating NSA climate mitigation contributions. To accomplish this task, DDL developed custom machine learning-aided algorithms and data dictionaries to harmonize these reports, which include data from more than a dozen disparate sources. These functions and data dictionaries form the ClimActor R package, an open-source software that allows for anyone to use our cleaning algorithms to harmonize climate actors’ data.
DDL then collaborated with the Open Earth Foundation to share its experience in harmonizing this data into a data model or schema. A data schema is a standardized framework for organizing and formatting data. In a climate context, this means developing a common structure for data related to climate actors, their actions and targets, and their relationships with one another, acting as a common language for data interoperability and enabling seamless exchange and understanding of climate action data. By adopting this schema, organizations can ensure consistency in data representation, making it easier to integrate and analyze information from different sources. This year was the first time DDL adopted the schema for organizing GCA report data.
Building Better Data Schema
For the 2023 GCA report, I worked with DDL post-doc Kaihui Song to enhance the interoperability of the data for the report. This was a two step process involving:
1- Harmonizing the names of actors through using the ClimActor R package
2- Formatting the data to align with the schema illustrated in Figure 1
Integrating the schema into this year’s data workflow involved breaking up and organizing the data into distinct subsections that could later be merged back together based on common identifiers, allowing for a more granular level of organization (Figure 1). For instance, if we wanted to compare the aggregated emissions data for actors across various sources, we would only have to extract the cleaned “Actor” and “EmissionsAgg”’ data files for our analysis. This was a more efficient manner of handling data, especially as the variables of interest shifted during different stages of our analysis.
Moreover, I also revisited and reformatted the data compiled for previous years’ GCA reports (2018-2022) to align with this newly adopted schema. This standardized formatting enhanced the degree of data interoperability across time. I was then able to create time series visualizations that track actors’ progress on commitments across the different iterations of the GCA report. This temporal data interoperability also enabled us to hone in on relevant actors and investigate how their climate commitments have been evolving, further enabling sustained climate accountability. To me, witnessing how data could tell a story across years underscored the importance of standardization.
On one hand, the process of using ClimActor to clean actor names showed me that even the seemingly small details, like consistent naming conventions, can significantly streamline analysis and comparison. On the other hand, I learned that schema and structure are powerful tools for translating data into narratives that foster meaningful change. Through working on this project, I gained a refined understanding of how data organization can enable more effective and efficient tracking and aggregation of climate progress. Ultimately, data interoperability empowers stakeholders to make informed decisions, hold actors accountable, and allow meaningful evaluation of financing, mitigation, and adaptation targets.
Recent Comments