Introductory Video
Data-Driven Envirolab has been tracking and aggregating climate commitments by local governments and businesses for the past few years. We do this because these are pivotal actors in accelerating climate action to the scales necessary to avoid dangerous levels of global warming. However, a major challenge when dealing with tens of thousands of actors is cleaning the data. Every data scientist is familiar with the tedium and frustration of cleaning dirty data. It feels like one is wading through a digital swamp — a boggy and buggy undertaking with no end in sight. Often, the cleaning takes much longer than the actual analysis itself. For example, the country Cote d’Ivoire may be recorded as “Ivory Coast”, “Côte d’Ivoire”, or “Republic of Côte d’Ivoire” in different databases. A lack of standardization of the country name prevents the aggregation of data from different sources.
To make this process more efficient for us and other researchers, we have developed ClimActor, a R package for standardizing the names of actors and cleaning climate commitment data (R is a popular open source programming language). We wanted this tool to be useful to as many people as possible, so we developed it to be domain-agnostic, meaning that it could be used in applications beyond non-state climate research. Pictured below is a vignette summarizing the package.
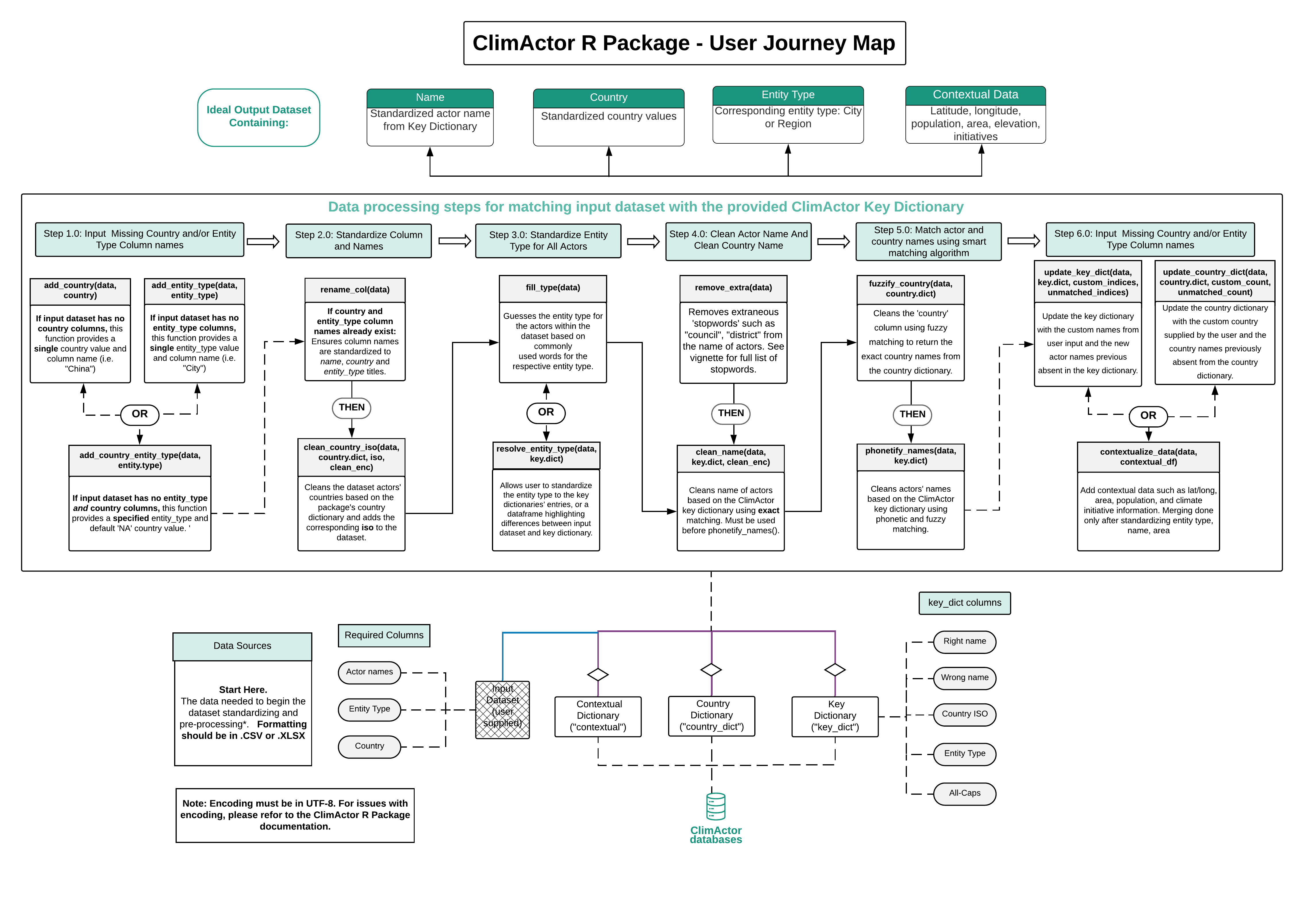
ClimActor contains functions corresponding to three stages of the data cleaning process — data preparation, standardization and pre-processing, and post-processing. The first stage, data preparation, is all about ensuring that three crucial columns — actor name, country, and entity type — are present in the dataset. Some datasets will have this information under different column names, or not at all, so this stage involves renaming or creating columns for this information.
The second stage, standardization and pre-processing, is where the bulk of the data cleaning happens. A series of functions allows ClimActor users to match and replace actor and country names with standardized versions using our key dictionary. The key dictionary contains commonly found variations of the actor name, for instance “Ivory Coast” and “Côte d’Ivoire”, alongside the standardized name (Cote d’Ivoire). For names that do not exactly match entries in the key dictionary, a function called fuzzify_country uses fuzzy matching algorithms to detect similar names in the key dictionary.
Once the actor names have been standardized, ClimActor’s post-processing functions allows users to easily add in contextual data, such as the country’s ISO code, area, population, climate initiatives committed to, and more. Users can also customize the key dictionary by adding in new entries that they come across, or even use their own key dictionaries, making it adaptable to different research goals.
Video Tutorial
To help you make the most of the package, watch the walkthrough led by our very own Zhi Yi Yeo, or follow the step-by-step documentation (vignette) available on our GitHub page.
We hope this guide was instructive and that the package will help smooth out the bumps in your data cleaning process. Our paper in Scientific Data is available here. If you have ideas for improvement or collaboration, we’d love to hear from you! Reach out to us at datdrivenlab@gmail.com
Where can we access the ClimActor dataset itself?
Hi Anna Elise, it’s available on our GitHub page. It should also be on Nature’s figshare soon but I just checked and it doesn’t look to be uploaded yet. I pinged them, but the latest version will always be on the GitHub: https://github.com/datadrivenenvirolab/ClimActor/tree/master/data-raw